#!/usr/bin/env python
# coding: utf-8
# # PLN (Procesamiento del lenguaje natural) con Python
#
# **Requisitos: Será necesario instalar la librería NLTK, además de descargar el corpus para las stopwords. Por defecto Conda incluye el paquete NLTK así como Google Colab. En el caso de que no estuviera instalado NLTK, ejecutar el siguiente chunk**
# In[2]:
# Ejecutar este chunk sólo si no está instalado NLTK
# Descomentar la siguiente línea para instalar la libraría:
#!conda install nltk
# In[1]:
import nltk
# In[4]:
nltk.download_shell()
#d) DOwnload:
#stopwords
# ## Obtener los datos
# Para el presente ejercicio, usaremos un dataset de [UCI datasets](https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection). Este dataset está en la carpeta **data**. El conjunto de datos está en inglés y cuenta con más de 5000 SMS. Para información ampliada sobre el conjunto de datos, consultar el fichero **readme**.
# Comprobamos primero el total de mensajes del conjunto de datos. Usaremos rstrip() para eliminar 'espacios' al final de cada línea (o retornos de carro):
# In[2]:
mensajes = [line.rstrip() for line in open('datos/SMSSpamCollection')]
print(len(mensajes))
# In[3]:
type (mensajes)
# In[4]:
mensajes [0:20]
# Una colección de textos se suele denominar "corpus". Podemos imprimir mensajes, mostrando además el número de SMS, usando **enumerate**:
# In[5]:
for num_mensaje, mensajes in enumerate(mensajes[:20]):
print(num_mensaje, mensajes)
#print('\n')
# El set de datos, tiene como separador \t (es un TSV), donde la primera columna nos indica si el mensaje es spam o no. La segunda columna contiene el cuerpo del SMS.
#
# A través de Machine Learning, vamos a entrenar un modelo para aprender a discriminar automáticamente cuando un SMS es span o no. El modelo lo podremos usar para clasificar SMS sin la variable clase.
#
# Podemos ver el proceso seguido, a través de la documentación oficial de SciKit Learn:
# 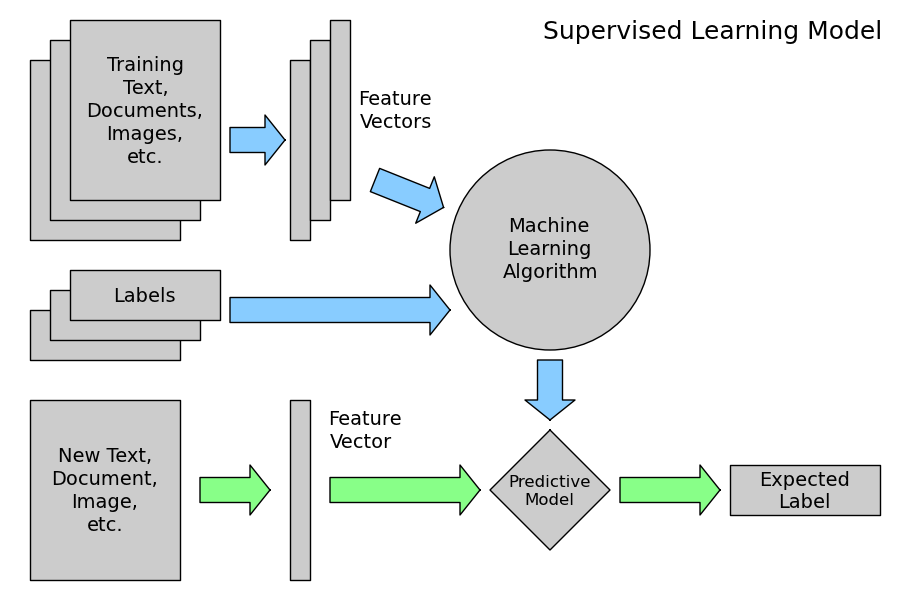 # In[6]:
import pandas as pd
# In[7]:
mensajes = pd.read_csv('datos/SMSSpamCollection', sep='\t',
names=["clase", "mensajes"])
mensajes.head()
# ## Análisis exploratorio inicial
# In[8]:
mensajes.describe()
# Agrupamos los datos en base a la clase y vemos que devuelve describe().
# In[9]:
mensajes.groupby('clase').describe()
# Para continuar, realizamos un análisis exploratorio para conocer los datos con los que estamos trabajando. Cuanto mayor sea el conocimiento que tengamos de los datos, mayor capacidad tendremos para el [feature engineering](https://en.wikipedia.org/wiki/Feature_engineering) (ingeniería de datos o factores).
#
# El enriquecimiento de los datos, puede ser mejorar de manera reseñable la capacidad predictiva de nuestro modelo, frente a un set de datos dado.
# In[10]:
mensajes['tamaño'] = mensajes['mensajes'].apply(len)
mensajes.head()
# In[11]:
mensajes.sort_values('tamaño', ascending=False)
# ### Visualización de los datos.
# In[12]:
import matplotlib.pyplot as plt
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
# In[13]:
plt.figure(figsize=(12,8))
mensajes['tamaño'].plot(bins=200, kind='hist')
# In[15]:
plt.figure(figsize=(12,8))
mensajes['tamaño'].plot.hist(bins=1000)
# Podemos jugar con el argumento bin que nos permite definir la granularidad o resolución del eje X. Para estos datos bins representa la longitud de los mensajes ¿Qué pasa cuando bins se acerca a 1000? Tenemos registros (mensajes)
# In[14]:
mensajes.sort_values('tamaño', ascending=False)
# Buscamenos el mensaje más extenso con 910 caracteres.
# In[15]:
mensajes[mensajes['tamaño'] == 910]['mensajes'].iloc[0]
# Olvidándonos del contenido del mensaje, nos centramos en la idea que ver si la longitud del mensaje influye en si es spam o no.
# In[16]:
mensajes.hist(column='tamaño', by='clase', bins=50,figsize=(12,6))
# A través del análisis exploratorio inicial, hemos obtenido una conclusión interesante, la tendencia a que un mensaje sea considerado spam aumenta con el tamaño del mensaje.
# ## Preprocesado del texto
# Los algoritmos de clasificación, implican convertir la conversión del set de datos en algún tipo de dataframe numérico (conversión del corpus a formato vector). La manera más sencilla es a través de una aproximación del tipo [bag-of-words](http://en.wikipedia.org/wiki/Bag-of-words_model) donde una palabra se representa por un número.
#
# Convertiremos por tanto mensajes en bruto (estado actual) en vectores (secuencias de números).
#
# Como primer paso separaremos a través de una funcion, cada mensaje en una lista de palabras. Posteriormente eliminaremos las palabras muy comunes (stopwords como 'the', 'a', ...) a través de la librería NLTK (https://www.nltk.org/book/). En este caso de uso usaremos las funciones básicas de la librería.
#
# Stopwords: https://es.wikipedia.org/wiki/Palabra_vac%C3%ADa
#
# Generamos una función que procese un mensaje y posteriormente a través de **apply()** lo procesaremos para todo el DataFrame.
#
# Eliminamos los signos de puntuación, para ello podemos usar el método **string**:
# In[17]:
import string
mens = 'Ejemplo mensaje! Atención: tiene un punto..'
# Comprobamos los caracteres para ver si son símbolos de puntuación
nopunc = [char for char in mens if char not in string.punctuation]
nopunc
# In[18]:
string.punctuation #elimina todo lo que sean puntuaciones
# In[19]:
# Juntamos los caracteres de nuevo para construir una cadena de texto.
nopunc = ''.join(nopunc)
nopunc
# In[20]:
mens
# Una vez eliminados los signos de puntuación, eliminamos las stopwords. En este ejemplo, el set de datos está en inglés, por lo que deberemos eliminar las stopwords inglesas. En la documentación de NLTF podemos encontrar las stopwords para cada idioma.
# In[21]:
from nltk.corpus import stopwords
nltk.download('stopwords')
# In[22]:
stopwords.words('english')
# Las StopWords para castellano son:
# In[23]:
stopwords.words('spanish')
# In[24]:
nopunc.split()
# In[25]:
# Eliminamos stopwords
clean_mens = [word for word in nopunc.split() if word.lower() not in stopwords.words('spanish')]
# In[26]:
clean_mens
# Este ejemplo está desarrollado para texto en castellano, pero el conjunto de datos está en inglés. Automatizamos el proceso para ejecutarlo sobre el total de datos en inglés.
# In[27]:
def procesado_texto(mens):
"""
Acepta una cadena de texto, y ejecuta:
1. Elimina todos los símbolos de puntuación
2. Elimina las stopwords
3. Devuelve una lista de texto limpio
"""
# Comprobar caracteres para eliminar cualquier símbolo de puntuación
nopunc = [char for char in mens if char not in string.punctuation]
# Unir los caracteres para generar un string de nuevo.
nopunc = ''.join(nopunc)
# Eliminar las stopwords (en este caso de uso, inglesas)
return [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]
# In[28]:
mensajes.head()
# Para procesar el set de datos, necesitamos 'tokenizar' los mensajes (convertir un conjunto de textos, en una lista de 'tokens' que son las palabras que nos interesan).
#
# Let's see an example output on on column:
#
# **Atención:**
# Podemos obtener 'warnings' debido a símbolos que no hemos tenido en cuenta o que no están en Unicode (como el símbolo de € o libra)
# In[29]:
# Comprobamos que funciona
mensajes['mensajes'].head(10).apply(procesado_texto)
# In[30]:
mensajes.head()
# ### Continuando con la Normalización
#
# Existen diferentes maneras para continuar normalizando textos. Una de ellas es el [Stemming](https://es.wikipedia.org/wiki/Stemming) otra de ellas podría ser la caracterización de cada palabra en función de si es un sustantivo, adjetivo, verbo, ...(http://www.nltk.org/book/ch05.html).
#
# NLTK tiene numerosas herramientas (que están muy bien documentadas). Tenemos que tener en cuenta, que en ocasiones el formato de las palabras y textos pueden estár abreviados o no están correctamente construidas a nivel sintáctico. Por ejemplo:
#
# _'Nah dawg, IDK! Wut time u headin to da club?'_
#
# vs.
#
# _'No dog, I don't know! What time are you heading to the club?'_
#
# Para esos casos será necesario hacer uso de los métodos avanzados disponibles en [NLTK book online](http://www.nltk.org/book/).
#
# ## Vectorización
# Hasta ahora, tenemos los mensajes como una lista de tokens (también conocidas como [lemas](http://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html)) y tenemos que convertir esos mensajes en un vector que los algoritmos de SciKit learn puedan usar.
#
# Convertiremos ahora cada mensaje (representado como una lista de tokens (lemas)), en un vector.
# Pasos:
# 1. Contar cuántas veces aparece cada palabra en cada mensaje (frecuencia):
#
# 2. Ponderar las apariciones, de manera que los tokens frecuentes 'pesen' menos (inversa de la frecuencia)
#
# 3. Normalizar los vectores
#
# El resultado que queremos obtener es una matriz de este tipo:
#
#
# In[6]:
import pandas as pd
# In[7]:
mensajes = pd.read_csv('datos/SMSSpamCollection', sep='\t',
names=["clase", "mensajes"])
mensajes.head()
# ## Análisis exploratorio inicial
# In[8]:
mensajes.describe()
# Agrupamos los datos en base a la clase y vemos que devuelve describe().
# In[9]:
mensajes.groupby('clase').describe()
# Para continuar, realizamos un análisis exploratorio para conocer los datos con los que estamos trabajando. Cuanto mayor sea el conocimiento que tengamos de los datos, mayor capacidad tendremos para el [feature engineering](https://en.wikipedia.org/wiki/Feature_engineering) (ingeniería de datos o factores).
#
# El enriquecimiento de los datos, puede ser mejorar de manera reseñable la capacidad predictiva de nuestro modelo, frente a un set de datos dado.
# In[10]:
mensajes['tamaño'] = mensajes['mensajes'].apply(len)
mensajes.head()
# In[11]:
mensajes.sort_values('tamaño', ascending=False)
# ### Visualización de los datos.
# In[12]:
import matplotlib.pyplot as plt
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
# In[13]:
plt.figure(figsize=(12,8))
mensajes['tamaño'].plot(bins=200, kind='hist')
# In[15]:
plt.figure(figsize=(12,8))
mensajes['tamaño'].plot.hist(bins=1000)
# Podemos jugar con el argumento bin que nos permite definir la granularidad o resolución del eje X. Para estos datos bins representa la longitud de los mensajes ¿Qué pasa cuando bins se acerca a 1000? Tenemos registros (mensajes)
# In[14]:
mensajes.sort_values('tamaño', ascending=False)
# Buscamenos el mensaje más extenso con 910 caracteres.
# In[15]:
mensajes[mensajes['tamaño'] == 910]['mensajes'].iloc[0]
# Olvidándonos del contenido del mensaje, nos centramos en la idea que ver si la longitud del mensaje influye en si es spam o no.
# In[16]:
mensajes.hist(column='tamaño', by='clase', bins=50,figsize=(12,6))
# A través del análisis exploratorio inicial, hemos obtenido una conclusión interesante, la tendencia a que un mensaje sea considerado spam aumenta con el tamaño del mensaje.
# ## Preprocesado del texto
# Los algoritmos de clasificación, implican convertir la conversión del set de datos en algún tipo de dataframe numérico (conversión del corpus a formato vector). La manera más sencilla es a través de una aproximación del tipo [bag-of-words](http://en.wikipedia.org/wiki/Bag-of-words_model) donde una palabra se representa por un número.
#
# Convertiremos por tanto mensajes en bruto (estado actual) en vectores (secuencias de números).
#
# Como primer paso separaremos a través de una funcion, cada mensaje en una lista de palabras. Posteriormente eliminaremos las palabras muy comunes (stopwords como 'the', 'a', ...) a través de la librería NLTK (https://www.nltk.org/book/). En este caso de uso usaremos las funciones básicas de la librería.
#
# Stopwords: https://es.wikipedia.org/wiki/Palabra_vac%C3%ADa
#
# Generamos una función que procese un mensaje y posteriormente a través de **apply()** lo procesaremos para todo el DataFrame.
#
# Eliminamos los signos de puntuación, para ello podemos usar el método **string**:
# In[17]:
import string
mens = 'Ejemplo mensaje! Atención: tiene un punto..'
# Comprobamos los caracteres para ver si son símbolos de puntuación
nopunc = [char for char in mens if char not in string.punctuation]
nopunc
# In[18]:
string.punctuation #elimina todo lo que sean puntuaciones
# In[19]:
# Juntamos los caracteres de nuevo para construir una cadena de texto.
nopunc = ''.join(nopunc)
nopunc
# In[20]:
mens
# Una vez eliminados los signos de puntuación, eliminamos las stopwords. En este ejemplo, el set de datos está en inglés, por lo que deberemos eliminar las stopwords inglesas. En la documentación de NLTF podemos encontrar las stopwords para cada idioma.
# In[21]:
from nltk.corpus import stopwords
nltk.download('stopwords')
# In[22]:
stopwords.words('english')
# Las StopWords para castellano son:
# In[23]:
stopwords.words('spanish')
# In[24]:
nopunc.split()
# In[25]:
# Eliminamos stopwords
clean_mens = [word for word in nopunc.split() if word.lower() not in stopwords.words('spanish')]
# In[26]:
clean_mens
# Este ejemplo está desarrollado para texto en castellano, pero el conjunto de datos está en inglés. Automatizamos el proceso para ejecutarlo sobre el total de datos en inglés.
# In[27]:
def procesado_texto(mens):
"""
Acepta una cadena de texto, y ejecuta:
1. Elimina todos los símbolos de puntuación
2. Elimina las stopwords
3. Devuelve una lista de texto limpio
"""
# Comprobar caracteres para eliminar cualquier símbolo de puntuación
nopunc = [char for char in mens if char not in string.punctuation]
# Unir los caracteres para generar un string de nuevo.
nopunc = ''.join(nopunc)
# Eliminar las stopwords (en este caso de uso, inglesas)
return [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]
# In[28]:
mensajes.head()
# Para procesar el set de datos, necesitamos 'tokenizar' los mensajes (convertir un conjunto de textos, en una lista de 'tokens' que son las palabras que nos interesan).
#
# Let's see an example output on on column:
#
# **Atención:**
# Podemos obtener 'warnings' debido a símbolos que no hemos tenido en cuenta o que no están en Unicode (como el símbolo de € o libra)
# In[29]:
# Comprobamos que funciona
mensajes['mensajes'].head(10).apply(procesado_texto)
# In[30]:
mensajes.head()
# ### Continuando con la Normalización
#
# Existen diferentes maneras para continuar normalizando textos. Una de ellas es el [Stemming](https://es.wikipedia.org/wiki/Stemming) otra de ellas podría ser la caracterización de cada palabra en función de si es un sustantivo, adjetivo, verbo, ...(http://www.nltk.org/book/ch05.html).
#
# NLTK tiene numerosas herramientas (que están muy bien documentadas). Tenemos que tener en cuenta, que en ocasiones el formato de las palabras y textos pueden estár abreviados o no están correctamente construidas a nivel sintáctico. Por ejemplo:
#
# _'Nah dawg, IDK! Wut time u headin to da club?'_
#
# vs.
#
# _'No dog, I don't know! What time are you heading to the club?'_
#
# Para esos casos será necesario hacer uso de los métodos avanzados disponibles en [NLTK book online](http://www.nltk.org/book/).
#
# ## Vectorización
# Hasta ahora, tenemos los mensajes como una lista de tokens (también conocidas como [lemas](http://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html)) y tenemos que convertir esos mensajes en un vector que los algoritmos de SciKit learn puedan usar.
#
# Convertiremos ahora cada mensaje (representado como una lista de tokens (lemas)), en un vector.
# Pasos:
# 1. Contar cuántas veces aparece cada palabra en cada mensaje (frecuencia):
#
# 2. Ponderar las apariciones, de manera que los tokens frecuentes 'pesen' menos (inversa de la frecuencia)
#
# 3. Normalizar los vectores
#
# El resultado que queremos obtener es una matriz de este tipo:
#
#
#
# | Mensaje 1 | Mensaje 2 | ... | Mensaje N |
#
#
# | Palabra 1 Count | 0 | 1 | ... | 0 |
#
#
# | Palabra 2 Count | 0 | 0 | ... | 0 |
#
#
# | ... | 1 | 2 | ... | 0 |
#
#
# | Palabra N Count | 0 | 1 | ... | 1 |
#
#
#
#
# En esta matriz, representamos por filas todos los tokens (únicos) detectados y por columnas cada uno de los mensajes del conjunto de datos. Haremos uso de **CountVectorizer** incluido en Scikit Learn.
#
# Debido a que no todas los tokens aparecerán en todos los mensajes, obtendremos una "matriz dispersa" donde el valor más habitual es el 0 -> [Matriz dispersa](https://en.wikipedia.org/wiki/Sparse_matrix).
# In[31]:
from sklearn.feature_extraction.text import CountVectorizer
# There are a lot of arguments and parameters that can be passed to the CountVectorizer. In this case we will just specify the **analyzer** to be our own previously defined function:
# In[32]:
# Éste proceso puede llevar un tiempo...
nube_palabras = CountVectorizer(analyzer = procesado_texto).fit(mensajes['mensajes'])
# Total elementos en la nube de palabras
print(len(nube_palabras.vocabulary_))
# In[33]:
# Una pequeña muestra de lo obtenido
pd.Series(nube_palabras.vocabulary_)[1:50]
# Extraemos la nube de palabras de un mensaje como vector...
# In[34]:
mensaje4 = mensajes['mensajes'][3]
print(mensaje4)
# En formato vector tendríamos...
# In[35]:
vector4 = nube_palabras.transform([mensaje4])
print(vector4)
print('\n')
print('Dimensiones: ',vector4.shape)
# Vemos que en el mensaje4, hay 7 palabras únicas (tras eliminar las stop words). 2 de ellas aparece dos veces, y el resto sólo una vez. Comprobamos a qué términos corresponden éstos elementos.
# In[36]:
print(nube_palabras.get_feature_names_out()[4068])
print(nube_palabras.get_feature_names_out()[9554])
# Ahora usaremos **.transform** en la nube de palabras obtenida y la convertimos en DataFrame
# In[37]:
mensajes_nube_palabras = nube_palabras.transform(mensajes['mensajes'])
# In[38]:
print('Dimensiones de la matriz dispersa: ', mensajes_nube_palabras.shape)
print('Total de elementos NO nulos: ', mensajes_nube_palabras.nnz)
# In[39]:
dispersion = (100.0 * mensajes_nube_palabras.nnz / (mensajes_nube_palabras.shape[0] * mensajes_nube_palabras.shape[1]))
print('dispersion: {}'.format(dispersion))
# Después de obtener la matriz con la nube de palabras, necesitamos normalizar lo obtenido. El objetivo es comprobar cómo de importante es cada término respecto del total y puede llevarse a cabo a través de [TF-IDF](http://en.wikipedia.org/wiki/Tf%E2%80%93idf), usando `TfidfTransformer` de Scikit-learn.
# In[40]:
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer().fit(mensajes_nube_palabras)
tfidf4 = tfidf_transformer.transform(vector4)
print(tfidf4)
# ¿Cuál es el IDF (inverse document frequency) para las palabras "u" y "university"?
# In[41]:
print(tfidf_transformer.idf_[nube_palabras.vocabulary_['u']])
print(tfidf_transformer.idf_[nube_palabras.vocabulary_['university']])
# Transformamos la nube de palabras en un corpus TD-IDF de una vez:
# In[42]:
mensajes_tfidf = tfidf_transformer.transform(mensajes_nube_palabras)
print(mensajes_tfidf.shape)
# ## Entrenando el modelo
# Puesto que ya tenemos los mensajes reprentados como vectores, podemos entrenar nuestro clasificador spam/ham. Podemos utilizar casi cualquier tipo de algoritmo de clasificación. Usaremos para este caso el clasificador Naive Bajes (http://www.inf.ed.ac.uk/teaching/courses/inf2b/learnnotes/inf2b-learn-note07-2up.pdf).
#
# [Naive Bayes](http://en.wikipedia.org/wiki/Naive_Bayes_classifier)
# In[44]:
from sklearn.naive_bayes import MultinomialNB
modelo_deteccion_spam = MultinomialNB().fit(mensajes_tfidf, mensajes['clase'])
# Ya tenemos el modelo, veamos cómo clasifica el mensaje 4:
# In[45]:
print('Predicho:', modelo_deteccion_spam.predict(tfidf4)[0])
print('Esperado:', mensajes.clase[3])
# Ya tenemos nuestro modelo clasificador de mensajes.
#
# ## Evaluación del modelo
# Comprobaremos ahora el desempeño de nuestro modelo con la predicción de todos los mensajes. Tenemos que tener en cuenta que no podemos usar el mismo set de datos para entrenar y testear el modelo. Puesto que no hemos particionado los datos al inicio, no podríamos comprobar el desempeño del modelo.
# ## Train Test Split
# In[46]:
from sklearn.model_selection import train_test_split
msg_train, msg_test, clase_train, clase_test = train_test_split(mensajes['mensajes'], mensajes['clase'], test_size=0.2)
print(len(msg_train), len(msg_test), len(msg_train) + len(msg_test))
# Hemos elegido en este caso un tamaño de la muestra de test del 20% (1115 mensajes de un total de 5572).
# ## Creación de un Pipeline
#
# El Pipeline es el código común que generará un modelo para cualquier problema de clasificación o regresión. También generan códigos para entrenamiento y prueba , transforma datos. [Pipeline](http://scikit-learn.org/stable/modules/pipeline.html)
#
# La salida de todo el proceso es un objeto modelo, que es persistente, se puede guardar y cargar para su análisis.
#
# In[48]:
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('nube', CountVectorizer(analyzer=procesado_texto)), # strings to token integer counts
('tfidf', TfidfTransformer()), # integer counts to weighted TF-IDF scores
('clasificador', MultinomialNB()), # entrenamiento multinomial NaiveBayes
])
# 'Pasamos' ahora los mensajes de texto y pipeline realizará el preprocesamiento por nosotros:
# In[53]:
pipeline.fit(msg_train,clase_train)
# In[54]:
from sklearn.metrics import classification_report
predicciones = pipeline.predict(msg_test)
# In[55]:
print(classification_report(clase_test,predicciones))
# Si quisiéramos usar otro clasificador, es muy sencillo a través de pipeline. En el siguiente ejemplo usaremos el clasficador RF
# In[52]:
from sklearn.ensemble import RandomForestClassifier
pipeline = Pipeline([
('nube', CountVectorizer(analyzer=procesado_texto)),
('tfidf', TfidfTransformer()),
('clasficador', RandomForestClassifier()),
])
# ¿Puedes comprobar el desempeño del clasificador RF? ¿Es mejor o peor que el de NB?
# ## Más recursos
#
# [NLTK Book Online](http://www.nltk.org/book/)
#
# [Kaggle Walkthrough](https://www.kaggle.com/c/word2vec-nlp-tutorial/details/part-1-for-beginners-bag-of-words)
#
# [SciKit Learn's Tutorial](http://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html)